HTTP-Statuscodes: Verwendung, Fehler & Tipps für Deine SEO-Performance
In diesem Beitrag erkläre ich Dir ein SEO-Basic-Thema, das nichtsdestotrotz wichtig ist: die http-Statuscodes. Wenn Du im Internet unterwegs bist, bist Du sicher schon mal über diese Responses gestoßen. Was http-Statuscodes sind, was es mit 200, 301, 302, 404, 410 & Co. auf sich hat, erfährst Du in diesem Blogbeitrag.

http-Statuscodes sind zwar SEO-Basics, aber sie haben es in sich! Erfahre hier alles, was Du dazu wissen musst.
Inhalt
- Was sind http-Statuscodes?
- Einfluss der Statuscodes auf Deine SEO-Performance
- SEO-relevante Statuscodes und deren Verwendung
- Statuscode 200: ok
- Statuscode 301: permanent Redirect
- Statuscode 302: temporary redirect – found
- Statuscode 401: unauthorized
- Statuscode 403: forbidden
- Statuscode 404: not found & Soft 404
- Statuscode 410: gone
- Statuscode 500: internal server error
- Statuscode 502 – bad gateway
- Statuscode 503: service unavailable
- Statuscode 418 – I’m a Teapot!
- Weitere (unbekanntere) Statuscodes
- Prüfung des http-Statuscodes & Sonderfälle
- Fazit
Was sind http-Statuscodes?
Der http-Statuscode ist immer die erste Antwort des Servers auf eine Anfrage eines Clients (z. B. eines Browsers). Über den Statuscode teilt der Server dem Client mit, ob seine Anfrage erfolgreich war. Ist die Antwort nicht erfolgreich (200), so gibt er über einen anderen Statuscode eine Auskunft darüber, was fehlerhaft (z. B. Seite nicht gefunden) ist oder wie die Anfrage erfolgreich werden kann (z. B. über eine Weiterleitung). Beginnen wir aber mit der Erklärung der verschiedenen Fachbegriffe:
Was ist ein Client?
Ein Client ist ein Programm auf Deinem PC bzw. auf dem Endgerät eines Netzwerks, mit dem der Server „spricht“ und Informationen austauscht. Darunter fallen zum Beispiel Webbrowser wie Chrome, Mozilla Firefox oder Safari, die mit Webservern kommunizieren und von ihnen die Informationen zur Darstellung der Seiten erhalten. Es gibt aber zum Beispiel auch E-Mail-Clients, die Mails von E-Mail-Servern abrufen oder versenden.
Was ist ein Server?
Unter dem Begriff „Server“ kann man zwei verschiedene Dinge verstehen:
Server als Hardware: Das ist ein Netzwerkrechner, der Ressourcen für andere Computer zur Verfügung stellt. Ihn bezeichnet man oft auch als „Host“. Auf dem Hardware-Server sind auch die Software-Server installiert. Grob gesagt ist er also der physische Speicherort.
Server als softwarebasierter Server: Das ist ein Programm, dessen spezieller Dienst von anderen Programmen (=Clients) genutzt werden kann. Grundlage dafür ist das Client-Server-Modell. Neben Web-Servern gibt es auch noch andere Server, zum Beispiel File-Server (u. a. FTP-Server), E-Mail-Server (IMAP/POP- oder SMTP-Server), Drucker-Server, Datenbank-Server (z. B. MySQL), VPN-Server (verschlüsselte, private Verbindungen auf ein Netzwerk) und Proxyserver, sowie noch einige andere, die ich an dieser Stelle nicht alle aufzählen möchte.
Das passiert, wenn Du eine Internetseite ansurfst:
Wenn Du eine Webpage besuchst, macht sich Dein Client in Form Deines Browsers an die Arbeit und bittet den softwarebasierten Web-Server (zum Beispiel Apache oder IIS) um Informationen. Dieser antwortet dem Browser und liefert ihm diese.
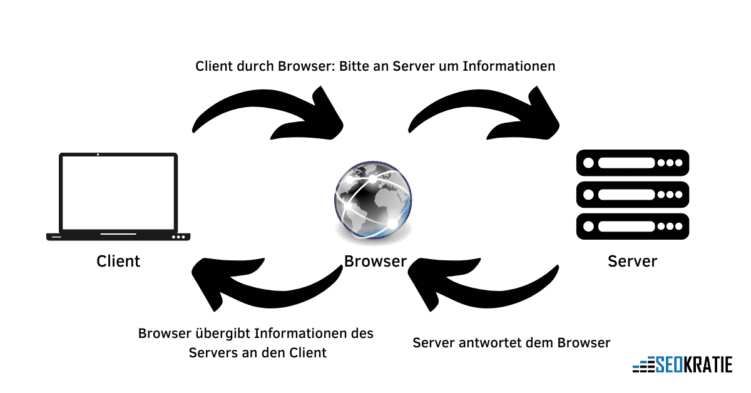
So funktioniert die Kommunikation des Clients zum Server über den Browser.
Ausgabe des http-Statuscode
HTTP steht für „Hypertext Transfer Protocol“. HTTP-Statuscodes sind ein dreistelliger digitaler Zahlencode, die der Web-Server dem Client zurückgibt und ihm den Status der Seite liefert. Sie beginnen immer mit den Ziffern 1,2,3,4, oder 5 die uns Aufschluss über die zugehörige Statusklasse des HTTP-Statuscodes gibt.

Die http-Statuscodes lassen sich in fünf Klassen einteilen. Kennst Du sie?
Die fünf Klassen der http-Statuscodes
Die http-Statuscodes lassen sich in fünf Klassen einteilen:
- 1xx: Der Server hat die Anfrage erhalten und die Kommunikation mit dem Client läuft. Dieser Statuscode weist den Client an, auf die endgültige Information zu warten.
- 2xx: Diese Gruppe von Statuscodes besagt, dass die Anfrage nicht nur eingegangen ist, sondern auch erfolgreich war.
- 3xx: Die Anfrage des Clients hat den Server erreicht, aber es ist ein weiterer Schritt des Clients notwendig, um die Anfrage erfolgreich abzuschließen.
- 4xx: Die Anfrage war fehlerhaft – der Fehler liegt dabei auf der Seite des Clients (zum Beispiel nicht gefundene Ressourcen oder fehlende Berechtigung).
- 5xx: Die Anfrage war fehlerhaft, der Fehler liegt jedoch auf der Seite des Servers (zum Beispiel Überlastung oder Wartung).
Einfluss der Statuscodes auf Deine SEO-Performance
Bei allen 2xx http-Statuscodes zieht Google die Indexierung in Betracht. Wenn allerdings ein Fehler wahrscheinlich ist und beispielsweise eine leere Seite erscheint, dann zeigt die Search Console einen Soft-404-Fehler an. Hier solltest Du darauf achten, dass diese Art von Fehlern berichtigt wird.
So kannst Du Soft-404-Fehler auf Deiner Website finden:
Die Daten kannst Du über die Google Search Console abrufen, indem Du in der Übersicht zur Abdeckung navigierst:
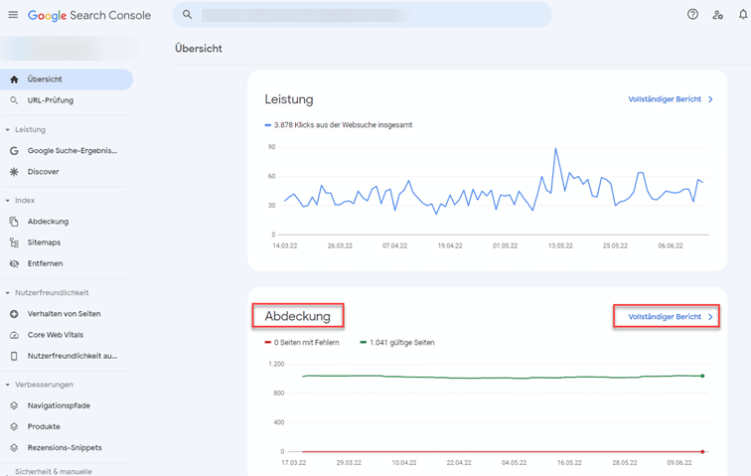
So findest Du den Abdeckungsbereich in der Google Search Console.
Von dort aus kannst Du die Seiten anzeigen lassen, die ausgeschlossen sind. Dort findest Du die Seiten, die Soft-404-Fehler sind:
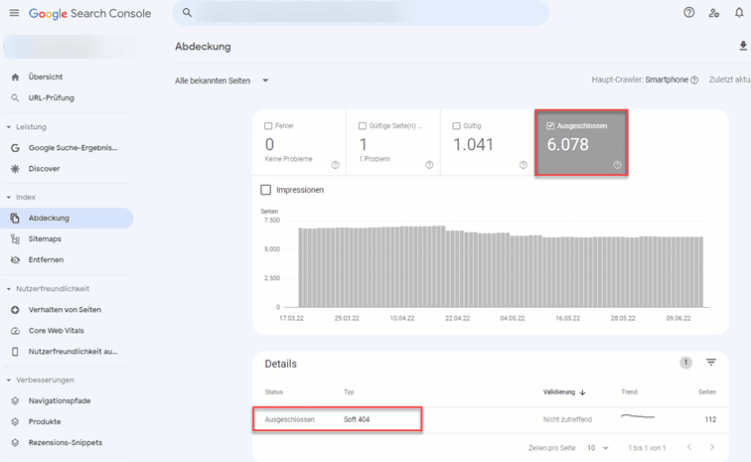
Deine Soft-404-Fehler findest Du unter den ausgeschlossenen Seiten.
Die 3xx Statuscodes sind alle Weiterleitungen. Dabei folgt der Googlebot laut Google Developers bis zu 10 Weiterleitungs-Hops. Wenn der Bot dort allerdings auf keinen Inhalt stößt, wird ein Weiterleitungsfehler angezeigt.
Tipp: Auf was Du auch achten sollst, sind Weiterleitungsketten und Endlosschleifen (Redirect Loops). Diese können entstehen, wenn eine Weiterleitung falsch gesetzt wurde und der Googlebot sich in einer Endlosschleife aus Redirects befindet. Spätestens ab dem zehnten Weiterleitungs-Hop stoppt der Bot und zeigt einen Fehler an.
So sieht eine Weiterleitungskette aus: URL A > URL B > URL C
So sieht eine Endlosschleife (Redirect Loop) aus: URL A > URL B > URL A > URL B …
Außerdem wichtig: Jede Weiterleitung kostet ca. 0,2 Sekunden an Ladezeit. Hast Du unnötige Weiterleitungsketten, erhöht sich dadurch also die Ladezeit, was wiederum schlecht für Deine SEO-Performance ist.
Wie Du Weiterleitungsketten und Redirect Loops mit dem Screaming Frog erkennen kannst, erfährst Du im Blogbeitrag 11 Anwender-Tipps zum Screaming Frog aus der SEO-Praxis.
Für die Indexierung bei Google werden 4xx Statuscodes nicht mitberücksichtigt. Bereits indexierte URLs können aus dem Index rausfliegen, wenn sie weiterhin eine 4xx Response zurückgeben. Diese Inhalte werden vom Googlebot ignoriert.
Statuscodes mit 5xx wiederum verlangsamen das Crawling der Bots wie dem Googlebot vorübergehend. Wenn eine URL bereits indexiert ist, bleibt sie im Index. Wenn die 5xx Response bestehen bleibt, werden diese letztlich auch aus dem Index entfernt.
SEO-relevante Statuscodes und deren Verwendung
Nicht alle Statuscodes sind für SEO relevant und beeinflussen Dein Ranking. Daher ist es wichtig zu wissen, welche Statuscodes Du im Blick behalten sollst. Um herauszufinden, welche Statuscodes Deine Seiten ausgeben, kannst Du die Seite crawlen mit beispielsweise Screaming Frog. Google hat die wichtigsten http-Statuscodes ausführlich in einem Beitrag in Google Search Central dokumentiert.
Statuscode 200: ok
Bestenfalls gibt der Großteil Deiner Seiten den http-Statuscode 200 zurück. Das ist der Regelfall: Die Anfrage des Clients war erfolgreich, sie wurde vom Server angenommen und die aufgerufene Ressource ist vorhanden. Sie wird an den Client gesendet und Deine aufgerufene Seite wird angezeigt. Achte darauf, dass nicht einfach jede URL – auch Phantasie-URLs – einen http-Status 200 ausgeben, denn sonst hast Du die weiter oben erwähnten Soft-404-Fehler.
Statuscode 301: permanent Redirect
Der http-Statuscode 301 ist die permanente Weiterleitung. Sie gibt die Antwort an den Server, dass die Ressource dauerhaft unter einer anderen Adresse zu finden ist. Suchmaschinenbots und Besucher werden direkt zu der neuen Seite weitergeleitet. Der Vorteil von 301-Weiterleitungen ist, dass diese die Linkpower weitergeben und die neue URL indexiert wird.
Ob Google Deine 301-Weiterleitung bereits akzeptiert hat, kannst Du über das URL-Prüftool der Google Search Console herausfinden:
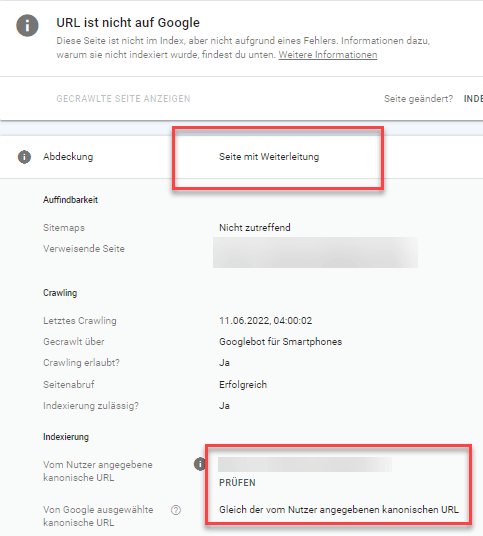
Zeigt das URL-Prüftool für Deine weitergeleitete Seite den Vermerk „Seite mit Weiterleitung“ an und unter der kanonischen URL findest Du Dein gewünschtes Weiterleitungsziel, weißt Du schon einmal, dass Google Deine Weiterleitung bereits gefunden.
Anwendung der 301-Weiterleitung:
Da es sich um einen Inhalt handelt, der nun auf einer anderen Seite zu finden ist, wird dieser Statuscode nur bei einem Domainwechsels oder einer URL-Strukturänderung verwendet.
Wichtig: Der Inhalt der Seite, auf die die Weiterleitung führt, sollte den ursprünglichen Inhalt entsprechen oder zumindest ähneln.
Ein typischer Anwendungsfall im SEO ist z. B. auch die Zusammenlegung von zwei sehr ähnlichen Seiten. Bei einer 301-Weiterleitung werden die Rankings der „alten“ URL in der Regel auf die „neue“ Adresse weitergegeben – sofern der Inhalt zusammenpasst:
Den Erfolg der Rankingübertragung kannst Du wunderbar in der Google Search Console überprüfen:
Vergleiche dazu das Ranking der alten URL mit der neuen URL, indem Du die Filter der GSC verwendest:
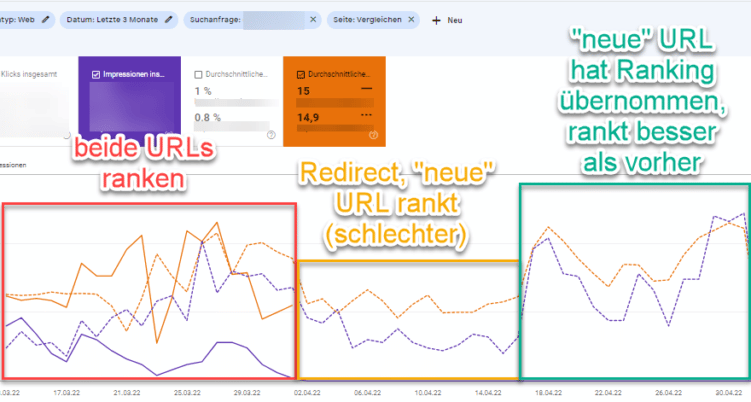
Der Vergleich der beiden URLs zeigt, wie die „neue“ URL nach dem Redirect anfängt besser zu ranken.

Mit der 301-Weiterleitung teilst Du Google mit, dass sich der Inhalt jetzt unter einer anderen URL befindet und es wird Linkjuice weitergegeben! Eine tolle Sache, oder?
Statuscode 302: temporary redirect – found
Während der Statuscode 301 besagt, dass eine Ressource nun dauerhaft verschoben wurde, sagt der http-Statuscode 302, dass die Ressource nur temporär verschoben wurde. Das bedeutet, dass der Inhalt der Seite in der Zukunft wieder unter der alten URL zu finden ist und diese erhalten bleibt. Pagerank geben übrigens laut Google alle Arten der Weiterleitungen weiter – sowohl 302 als auch 301. Der Unterschied ist lediglich, dass bei einer 302-Weiterleitung die Ziel-URL nicht gecacht wird.
Der http-Statuscode 401 gehört zu den fehlerhaften Responses. Mit diesem Statuscode wird ausgesagt, dass die Anfrage des Clients vom Server aufgrund von einer fehlenden oder ungültigen Authentifizierung abgelehnt wurde.
Statuscode 403: forbidden
Dem Statuscode 401 ähnelt der http-Statuscode 403. Dieser bedeutet „forbidden“. Hier hat der Server die Anfrage des Clients zwar verstanden, weigert sich jedoch diese zuzulassen. Der Zugriff ist dauerhaft verboten. Das kann zum Beispiel bei Seiten sein, die mit einem Passwort geschützt sind wie Accounts von E-Commerce Shops, die einen Login benötigen. Das kann eine bestimmte Aktion des Webmasters gewesen sein, z. B. dass bestimmte Bots von Tools oder IP-Adressen gesperrt werden, aber es kann auch unbewusst passieren, wenn Du zum Beispiel einen internen Link auf ein (noch gesperrtes) Verzeichnis Deiner Webseite gesetzt hat. Besonders dramatisch ist es, wenn Du aus Versehen den Googlebot aussperrst – so passiert bei einem Kunden von uns:
- Beim Aufrufen einer Seite identifiziert sich der Browser mit seiner „Kennung“, dem
sogenannten „User-Agent“. - Normale Browser von Nutzern haben einen User-Agent wie „Firefox“ oder „Chrome.
- Ruft man die URLs des Projekt mit diesen User-Agents auf, werden die Seiten korrekt angezeigt.
- Technisch erkennt man das daran, dass der HTTP Status-Code 200 („OK“) zurückgegeben
wird:
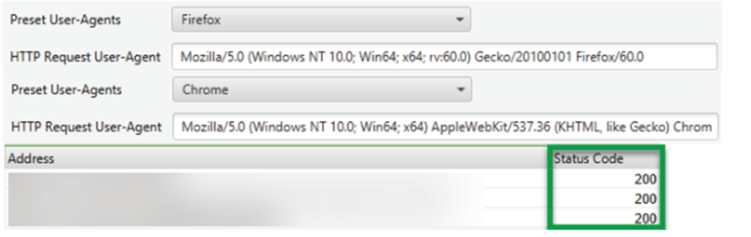
Screenshot aus dem Screaming Frog: der Statuscode 200 wird ausgegeben.
- Google identifiziert sich mit dem User-Agent „Googlebot“ oder „Googlebot Smartphone“.
- Bei Verwendung dieses User-Agents erhält man aber den Status-Code 403 („Forbidden“). Der Googlebot wird also vom Besuch der Website ausgesperrt:
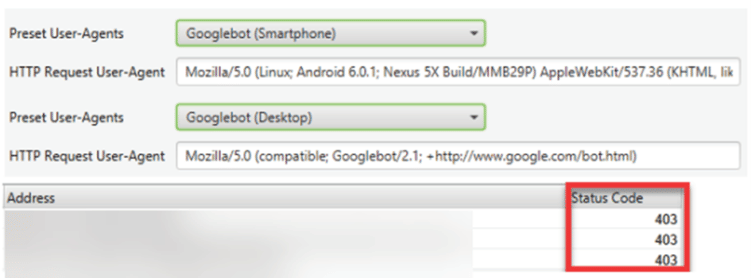
Nun wird der Statuscode 403 – forbidden ausgegeben.
Wichtig: Es ist hochriskant, den Googlebot von seiner eigenen Seite auszusperren. Bitte nicht nachmachen!

You shall not pass! Eintritt verboten mit dem http-Statuscode 403!
Statuscode 404: not found & Soft 404
Der http-Statuscode 404 sagt aus, dass die angeforderte Ressource im Moment nicht gefunden werden kann. Eine Fehlerseite wird ausgespielt. Oft liegt das daran, dass Tippfehler enthalten sind, Links falsch gesetzt oder Inhalte gelöscht wurden. Dieser Statuscode ist grundsätzlich nicht schlecht. Der http-Status 404 gehört in einer gewissen Menge zu einer gesunden Seitenarchitektur dazu. Eine gut eingerichtete 404-Fehlerseite, die ausgespielt wird, kann den Nutzern weiterhelfen. Zu vermeiden sind häufige 404-Responses, insbesondere bei wichtigen Seiten. Daher gibt es sowohl Chancen als auch Risiken für 404-Statuscodes.
Soft 404-Fehler sind Websites, die den angeforderten Inhalt nicht mehr anzeigen, aber keinen 404-Fehler ausgeben. Es wird dadurch fälschlicherweise der Statuscode 200 ausgegeben.
Für Nutzer und Suchmaschinen ist es nicht gut, wenn nach einem Inhalt gesucht wird und die Seite keinen Fehlercode ausgibt, sondern Content, der nicht der Suchanfrage entspricht. Die Empfehlung von Google ist, hier mit dem 404-Statuscode zu arbeiten. Zusätzlich kann die angezeigte Fehlerseite optimiert werden, damit die Nutzer weiterhin auf der Website bleiben.

Der 404-Fehler, einer der wohl bekanntesten http-Statuscodes!
Statuscode 410: gone
Dieser http-Statuscode sagt aus, dass der Zugriff auf die Ressource nicht mehr stattfinden kann, weil diese permanent gelöscht wurde.
Wenn Du Dir nicht sicher bist, ob die Ressource nur temporär oder permanent nicht vorhanden ist, sollte der http-Statuscode 404 verwendet werden.
Statuscode 500: internal server error
Der http-Statuscode 500 gehört zu den serverseitigen Codes und beschreibt den Internal Server Error, also den internen Serverfehler. Die Ressource, die der Client angefragt hat, kann aufgrund des Serverfehlers nicht angezeigt werden. Unter den Statuscode 500 können sehr viele Serverfehler fallen, daher ist er nicht sehr aussagekräftig. Ein weiterer Grund, wieso der 500er-Statuscode ausgegeben wird, sind fehlerhafte Einträge in der .htaccess-Datei.

Interner Serverfehler? Ein Fall für den Statuscode 500!
Statuscode 502 – bad gateway
Dieser Statuscode besagt, dass die Kommunikation zwischen dem Client und dem Server nicht funktioniert. Ursache dafür kann auf der Seite des Nutzers, des Internet-, oder des Hostinganbieters liegen. Die Nutzer Deiner Website kommen so nicht auf den Inhalt der angefragten Seite. Wenn der Fehler öfter auftritt, kommen die Nutzer nicht mehr wieder. Diese negativen Nutzersignale in Kombination mit dem http-Statuscode können langfristig dazu führen, dass es zu Ranking-Verlusten und sogar zur Entfernung aus dem Index kommen kann.
Ähnlich dazu ist der Statuscode 503. Dieser sagt aus, dass der Server temporär nicht zur Verfügung steht. Dieser http-Statuscode wird beispielsweise verwendet, wenn der Server überlastet ist oder gewartet wird. Achte darauf, dass dieser Statuscode nur temporär ist, damit Deine Seite nicht an Rankings verliert oder aus dem Index fliegt.
Tipp: Im Header-Feld „Retry-After“ kann der Zeitpunkt angegeben werden, wann der Server voraussichtlich wieder verfügbar ist.
Statuscode 418 – I’m a Teapot!
Der wohl wichtigste Statuscode was SEO betrifft, ist der http-Statuscode 418 (Achtung, Ironie!). Dieser Responsecode wurde 1998 von der Requests for Comments eingeführt und besagt: „I’m a teapot!““. Er ist Teil der Reihe von Aprilscherzen. 2014 hat Google ihn wiederentdeckt und aufgenommen:

Teatime bei Google mit dem Statuscode 418.
Der 418-Statuscode mit der Teekanne ist natürlich nicht SEO-relevant. Google behandelt ihn zwar wie einen Statuscode 200, wir raten Dir trotzdem dringend davon ab, ihnzu verwenden.
Weitere (unbekanntere) Statuscodes
Die Statuscodes, die in diesem Abschnitt genannt werden, sind eher unbekannt. Hier werden zwei proprietäre Statuscodes genannt und erklärt.
Statuscode 906
Wenn bei der Anfrage vom Client zum Remote-Server bei der Übermittlung ein Fehler aufgetreten ist, dann wird der Statuscode 906 ausgegeben. Die Anfrage muss vom Client nochmal gesendet werden.
Du willst keine unserer Beiträge mehr verpassen und auf dem Laufenden bleiben? Abonniere jetzt unseren Newsletter und erhalte jeden neuen Seokratie-Beitrag per E-Mail direkt in Dein Postfach!
Jetzt abonnierenStatuscode 950
Auch der 950 http-Statuscode gehört zu den proprietären Statuscodes. Wenn dieser ausgegeben wurde, ist bei der Interpretation einer Administrator-Anfrage des Clients ein Fehler passiert. Wie beim Statuscode 906 muss die Anfrage meist erneut gesendet werden.
Prüfung des http-Statuscodes & Sonderfälle
Um einen Überblick über Deine Seite zu bekommen, solltest Du sie regelmäßig crawlen. So kannst Du Fehler in Deinen http-Statuscodes frühzeitig erkennen und beheben.
Hattest Du schon mal den Fall, dass die robots.txt-Datei über 30 Tage lang einen Serverfehler ausgibt? Das kann vorkommen. So solltest Du damit umgehen: Wenn bereits seit mehr als 30 Tagen von der robots.txt-Datei ein Serverfehler-Statuscode zurückgegeben wird, dann verwendet Google die letzte gespeicherte Kopie der robots.txt-Datei, die im Cache liegt. Wenn diese nicht mehr verfügbar ist, geht Google davon aus, dass keine Crawling-Einschränkungen bestehen. Weitere Informationen dazu kannst Du bei Google Developers nachlesen.
Ein Tipp zum Thema wechselnder Statuscode:
Ein sich ständig wechselnder Statuscode wirft Dir Rätsel auf? Daran könnten mehrere verwendete Server schuld sein. Diesen spannenden Fall hat Luisa in einem Blogbeitrag „SEO aus der Praxis: 4 spannende SEO-Fälle“ gelöst.

Geschafft, nun bist Du ein Experte oder eine Expertin in Sachen http-Statuscodes!
Fazit
Nach dem Lesen von meinem Blogbeitrag bist Du nun bestens informiert, was http-Statuscodes und deren Verwendung im SEO angeht. Wie arbeitest Du mit Statuscodes? Ich freue mich von Deinen Erfahrungen damit in den Kommentaren zu lesen!
Bilder: Adobe Stock: Titelbild: Argus, Bild 1: eigene Darstellung, Bild 2: Thapana_Studio, Bild 3: Screenshot, Bild 4: Screenshot, Bild 5: Screenshot, Bild 6: Screenshot,Bild 7: iLee, Bild 8: Screenshot, Bild 9: Screenshot, Bild 10: leremy, Bild 11: Assemit, Bild 12: leremy, Bild 13: Screenshot, Bild 14: Jess rodriguez





