SEO aus der Praxis: 4 spannende SEO-Fälle
Heute gewähre ich Dir einen Blick hinter die Kulissen unserer SEO-Arbeit: Anhand von 4 Fällen zeige ich Dir, warum ich persönlich SEO gerne mit „Diagnostik in der Tierarztpraxis“ vergleiche – auch ein Tier sagt Dir nicht, wo es „weh tut“. Meine Kollegen wählen oft eher den Begriff der „Detektivarbeit“ und auch dieser trifft voll zu.

SEO-Detektiv in Arbeit.
Ein Klassiker: Die große Anzahl „komischer“ Links
Wir beginnen mit einem echten Klassiker: Du machst einen Crawl und sortierst nach URL. Beim Darüber-Scrollen, manchmal sogar noch während der Crawl läuft, fällt Dir eine große Menge an seltsamen URLs nach einem bestimmten Muster auf, zum Beispiel so etwas:
https://wwww.beispiel.de/kleines-wunder/umweltschutz/umweltschutz/umweltschutz/umweltschutz/[noch-4-x-umweltschutz]/
oder so etwas:
![]()
Ich finde, das wirkt schon irgendwie wie Kunst, oder?
Schritt 1: Was ist der Beginn dieser URLs und wo entstehen Sie?
Wenn Dir „komische“ URLs in einem Crawl auffallen ist das erste Vorgehen immer gleich:
- Finde die vermutlich erste komische URL mit diesem Muster:
- Dazu sortierst Du Deinen Crawl einfach alphabetisch, indem Du auf das URL-Feld klickst. Das funktioniert eigentlich bei allen Tool gleich:

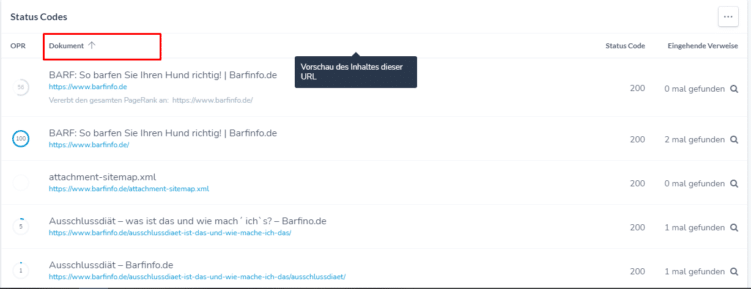
Hier einmal am Beispiel RYTE. Gehe erst in den Bericht „Indexierbarkeit > Statuscodes“ und klicke dann auf die Spalte „Dokument“.
- Dann scrollst Du zu den „komischen“ URLs. Hast Du einen besonders großen Crawl, kannst Du vorher auch noch nach dem „komischen“ Bestandteil der URL filtern.
- Dazu sortierst Du Deinen Crawl einfach alphabetisch, indem Du auf das URL-Feld klickst. Das funktioniert eigentlich bei allen Tool gleich:
- Finde heraus an welcher Stelle auf diese Ursprungs-URL verlinkt wird:
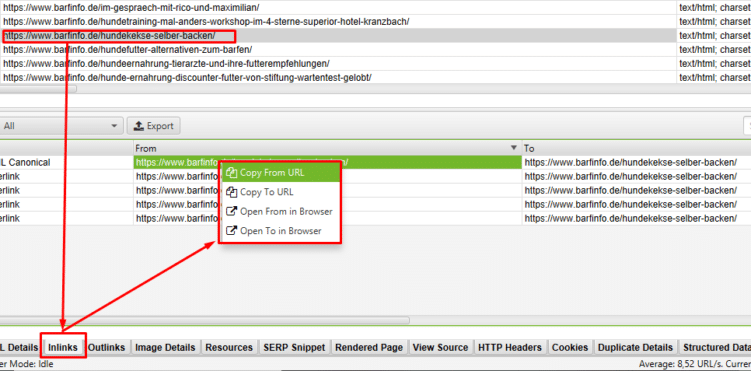
- Klicke jetzt auf die erste Ursprungs-URL und siehe Dir die „Inlinks“ (eine Liste aller URLs, die auf diese URL verweisen) an.
- Rufe die Quell-URL auf und suche den Link. Dabei kann Dir die Linkadresse, aber auch der Linktext helfen. Suche im Zweifel im Quelltext der Seite, denn nicht jeder Link ist sichtbar auf der Seite.
Schritt 2: Korrigiere den Link // Lass ihn korrigieren
Jetzt, wo Du weißt, an welcher Stelle diese komischen URLs entstehen, kannst Du ihre Entstehung verhindern (lassen). Entweder Du hast die Möglichkeit den Ursprungs-Link direkt selbst zu korrigieren oder Du kannst der IT direkt weitergeben an welcher Stelle diese Links entstehen.
Was war die Ursache in unseren beiden Fällen?
Ich möchte Dich natürlich nicht im Ungewissen lassen, was die oben genannten Beispiele anbelangt. Die „Umwelt-Schutz“-URLs sind dabei ein echter Klassiker. Die URL https://www.beispiel.de/umweltschutz wurde relativ im Footer der Domain verlinkt. Der Teufel liegt im Detail: Dabei wurde der erste Slash vergessen, also:
<a href="umweltschutz/">Umweltschutz</a>
anstelle von
<a href="/umweltschutz/">Umweltschutz</a>
Das bedeutet, dass der Crawler diese URL immer als lokale URL der URL und nicht der Domain interpretiert hat, zum Beispiel: https://www.beispiel.de/tischlampen/umweltschutz/ anstelle von – wie eigentlich gewünscht – https://www.beispiel.de/umweltschutz/. Da diese falschen URLs zu allem Überfluss auch noch aufrufbar waren, sind so sehr schnell mehrere Tausend URLs entstanden.
Im zweiten Beispiel entstand eine Kette hinter einem seitenweiten Button. Anstatt hier immer auf die korrekte, finale URL zu verlinken, wurde hier für jede URL eine eigene ID generiert, die mit ~ angehängt wurde. Auch die ~-URLs waren aufrufbar und generierten wiederum neue ~-Adressen.
Der verschwundene Title
Diesen Fall hat mein Kollege Felix beigesteuert. Plötzlich schlechtere Klickraten, verschlechterte Ranking und nicht mehr in Google ausgespielte Title gaben ihm ein Rätsel auf. Im Quelltext wurde der (optimierte) Title korrekt angezeigt, auch oben im Tab war er zu sehen. Google hat ihn aber partout nicht angezeigt.
Tipp: Wie schaut der ausgeführte Code aus?
Wenn Dir im „normalen“ Quellcode (also über STRG + U) alles normal vorkommt, dann wirf immer mal auch einen Blick auf den ausgeführten Code, z.B. über die Entwicklertools (STRG + SHIFT + C). In den Dev-Tools wird dann nicht der Quelltext einer Website angezeigt, sondern dessen Interpretation durch den Browser („ausgeführter Code“). Beim Quelltext handelt es sich um den Code, den der Entwickler geschrieben hat. Innerhalb der Entwicklertools wird daher möglicherweise mehr, weniger oder anderer Code gezeigt.
Zusätzlicher Code im <head>
Bei genauerer Betrachtung gab es aber doch einen Unterschied! Im <head>-Bereich fand sich auf einmal ein div-Tag, das dort nicht hingehörte. Dieses wurde mit JavaScript nachträglich eingefügt. Offensichtlich führte das dann dazu, dass der Google-Bot alles nach dem div-Tag – also auch das Title-Tag – nicht mehr ausgelesen hat! Nach dem Entfernen des div-Tags war alles wieder normal.
Knifflige Ranking-Schluckaufs
Dieser Fall hat mich auch besonders beschäftigt. Im Monitoring fielen immer wieder Tage auf, an denen einzelne Keywords plötzlich deutlich schlechter rankten. Diese „Schluckaufs“ traten regelmäßig auf – aber nicht zeitgleich bei den betroffenen Keywords:
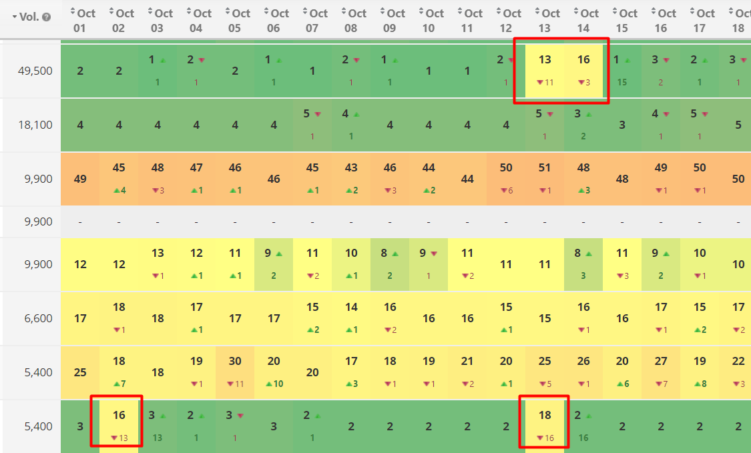
Immer wieder rankten an einzelnen Tagen Keywords plötzlich kurzzeitig schlechter
Der Blick in die Google Search Console
Erst dachten wir an einen Fehler im Tool, allerdings ließen sich die Rankingverschlechterungen und teilweise -ausfälle auch in der Google Search Console beobachten:
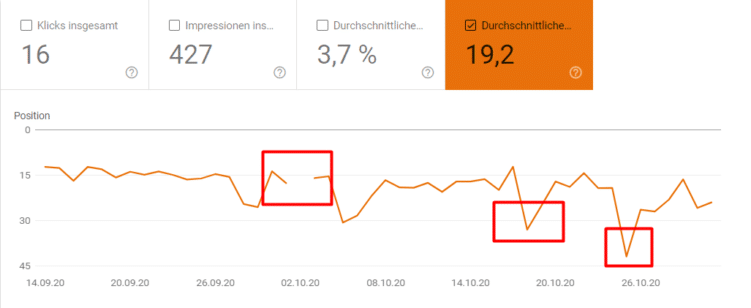
An diesem Keyword sah man ganz deutlich, dass an einzelnen Tagen das Ranking weg oder deutlich schlechter war.
Wir verglichen dann die Daten der Schluckaufs mit den Crawlingstatistiken: Dabei fiel auf, dass es zwar immer wieder Crawling-Peaks gab, diese oft, aber nicht immer, mit den Ranking-Verschlechterungen zusammenhingen.
Der Blick in die Logfiles
Spätestens jetzt war klar: Eine Logfile-Analyse steht an. Diese offenbaren uns zwei Dinge:
- Die Crawling-Peaks aus der GSC finden sich auch in den Logfiles
- Besonders zwei URLs werden zu den Peaks häufig gecrawlt. Es ist also kein allgemein vermehrtes Crawling, sondern es konzentriert sich auf die oberen zwei URLs:

Besonders zwei URLs wurden sehr häufig gecrawlt.
Erstere wurde vom Bot immer mit 200 zurück geliefert, lieferte dann aber 405. Die zweite wechselte mehrmals ihren Statuscode: 2xx von 200 auf 404, letzter Response Code in den Logfiles 200, danach beim beim Abruf 404. Die beiden URLs sind Ajax-Requests gedacht, die Teile der Seite aktualisieren. Die sollten eigentlich nicht direkt vom Crawler aufgerufen werden, daher haben wir sie über die robots.txt gesperrt.
Anzahl gecrawlter URLs
Interessanterweise gab es außerdem immer wieder Peaks in der Anzahl der gecrawlten URLs, die nicht analog zu den Event-Peaks waren (das macht Sinn, denn die Event-Peaks kommen nur von den oben genannten zwei URLs):
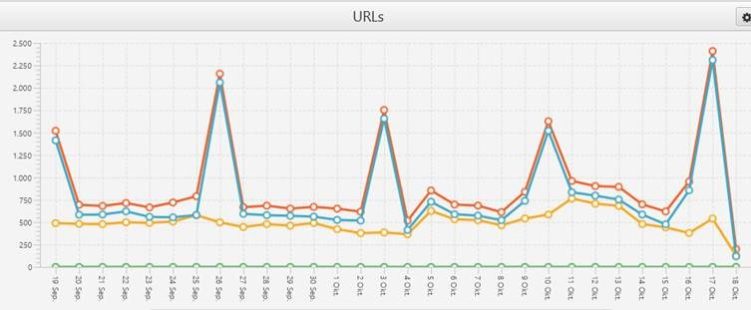
Alle 7 Tage gab es Peaks in der Anzahl gecrawlter URLs.
Diese URL-Peaks kamen regelmäßig alle 7 Tage und betrafen vor allem Bilder-Cache-URLs. Wir haben bereits häufiger beobachtet, dass Google im Abstand von 7 Tagen Bilder crawlt. Allerdings typischerweise eher der Image-Bot, in diesem Fall war es der Smartphone Bot. Dem würde ich per se nicht zu viel Bedeutung zuweisen. Zwischen unseren Rankingschluckaufs lagen statt 7 Tagen oft ca. 9 Tage. Sie bewegten sich jedoch häufig genau um die Daten der URL-Peaks herum.
Das Positive daran war: Die Rankings um diese Tage herum waren immer nur sehr kurz weg, teilweise in der GSC nicht rekonstruierbar. Außerdem kamen sie sehr zuverlässig sehr schnell wieder, so dass es sich nicht auf den Traffic auswirkte. Wir haben dann herausgefunden, dass diese Peaks immer mit der Erneuerung des Bilder-Cache zusammenhing, wenn neue Produkte eingespielt wurden.
Was ist mit den anderen Ausfällen?
Wir konnten also fast alle Schluckaufs klären. Es blieben aber noch einige Tage übrig, für die wir in den Logfiles keinen Zusammenhang feststellen konnten. In der (Tier)medizin gibt es folgenden Spruch: „Jeder Patient hat ein Recht auf mehrere Krankheiten!“ Bei einigen der verschlechterten Rankings fiel auf, dass statt der eigentlichen URL plötzlich eine andere für das Keyword gerankt wurde – und das deutlich schlechter.
Eine Ursache dafür kann ein Crawling- oder Server-Problem sein: Google crawlt die URL, erreicht sie nicht, und rankt stattdessen eine andere URL (schlechter). Beim nächsten Crawl klappt es wieder und das Ranking ist wieder da.
Gefällt Dir dieser Blogpost? Wenn Du regelmäßig die neuesten Trends im Online Marketing mitbekommen willst, dann abonniere jetzt unseren Newsletter. Zu Beginn des kostenlosen Abonnements bekommst Du täglich jeden Tag eine Mail, um Dich fit in SEO zu machen - 5 Tage lang. Über 83.000 Abonnenten vertrauen uns.
In unserem Fall hat RYTE zu einschlägigen Daten Timeouts aufgezeichnet:

Passend zu einigen Rankingschluckaufs gab es wohl Fehler beim Aufrufen der URL.
Fazit für die Rankingschluckaufs:
Insgesamt wurde Folgendes angepasst:
- Sperrung der AJAX-URLs über die robots.txt
- Bilder-Cache-URLs: keine Maßnahme
- Serverkonfiguration optimiert
Und jetzt die Gretchenfrage: Was hat es gebracht? Seit den Anpassungen sind die Ranking-Schluckaufs fast vollständig verschwunden. Hatten wir vorher mehrere dieser Lücken pro Monat, so waren es im Februar 2021 lediglich zwei Keywords, die auch nur kurzzeitig deutlich schlechter gerankt haben. Dieser Ausfall konnte in der Google Search Console auch nicht nachvollzogen werden, so dass er anscheinend wirklich von sehr kurzer Dauer gewesen sein muss.
Die wechselnden Tags
Die folgenden zwei SEO-Fälle gehören zu meinen Lieblings-Schwenks aus meinen SEO-Dasein. Einer trat bereits vor mehreren Jahren auf. Die meisten SEOs von Euch werden die LRT-Redirect Trace kennen. Es zeigt einem den Statuscode, die Ladezeit, sowie u.a. auch den Canonical einer Seite:

Das Link Redirect Trace Browser Plugin finde ich im SEO-Alltag sehr hilfreich.
Canonical wechsel Dich?
Beim Aufrufen der Kunden-Webseite fiel mir plötzlich auf, dass eine URL per Canonical auf eine andere wies – was in diesem Fall nicht gewünscht war. Per se ist das zwar ärgerlich, aber noch nichts besonders ungewöhnliches. Nun kommt das wirklich Interessante: Beim Refresh der URL zeigte der Canonical plötzlich wieder auf die URL selbst. Ich zweifelte erst an mir selbst, rief die URL erneut auf – keine Veränderung. Ich wiederholte das ganze und da – plötzlich – veränderte sich wieder das Canonical Symbol des Link-Redirect-Trace: Der Canonical zeigte wieder auf die andere URL.
Missing hreflang?
Der zweite Fall trat erst vor ein paar Wochen auf, wieder bei Felix. Bei jedem dritten Aufruf einer URL änderten sich plötzlich die hreflang. Das war dann wirklich ein ziemliches Chaos: Mal sind auf derselben URL nur DE, AT und CH in den hreflangs enthalten, dann zusätzlich auch NL und BE und dann waren plötzlich überhaupt keine hreflangs vorhanden.
Dies war dann auch die Erklärung dafür, warum in AT immer mal wieder die deutsche Domain rankte:
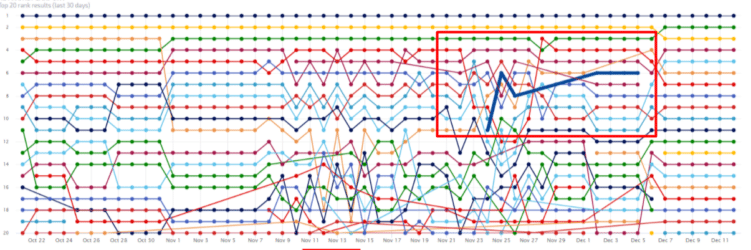
orange (AT) und dick-blau (DE) im Wechsel.
Ihr Serverlein kommet
Das Problem lag in beiden Fällen darin, dass mit mehreren Servern gearbeitet wurde. Diese lieferten dann unterschiedliche Webseiten-Versionen aus. Wie das technisch möglich ist – das kann ich nicht beantworten. Ich kann aber sagen: Für das SEO ist das nicht förderlich 😉
Als SEO wird Dir nicht langweilig
Diesen Spruch kann ich zu 100% unterschreiben und er ist einer der Gründe, warum ich meinen Job so sehr liebe. Es gibt immer wieder knifflige Fälle zu lösen, neue Erfahrungen zu machen und spannende Strategien anzuwenden. Du hast auch Lust auf Herausforderungen? Dann werde doch gerne Teil unseres Teams!
Titelbild: © gettyimages / rod2334






Hallo Luisa,
toller Praxis-Beitrag! Welches Tool habt ihr dort für die Rankingüberwachung genutzt?
LG
Stefan
Hi Stefan,
wir setzen auf mehrere Tools: Der farbige Screenshot ist aus dem Rankranger, parallel haben wir aber auch den Search Success von ryte im Einsatz.
Liebe Grüße
Luisa