Duplicate Content: Gefahren verstehen, finden & vermeiden
Vage haben die meisten Webseitenbetreiber davon gehört: Duplicate Content ist gefährlich! Google mag das nicht! Stimmt auch. Aber das ist kein Grund zur Panik. Zumindest nicht mehr. Denn hier erfährst Du, was sich dahinter verbirgt und worauf Du achten musst.

Meine Duplikate können ganz schön nervig sein.
Was ist Duplicate Content?
Duplicate Content (also „doppelte Inhalte“, kurz „DC“) sind Inhalte, die identisch auf mehreren Seiten im Internet vorkommen. Es handelt sich dabei nicht nur um kopierte Texte, sondern vor allem um komplett identische Einzelseiten. Es wird unterschieden in internen und externen Duplicate Content: Intern bedeutet, die gleichen Inhalte sind auf einer Domain – also beispielsweise auf Seokratie.de. Extern bedeutet, dass die Inhalte auf mehreren Domains vorkommen.
Duplicate Content verursacht Suchmaschinen wie Google Probleme. Deshalb werden dort die Inhalte der betroffenen Seite schlechter gefunden oder gar herausgefiltert. Damit eine Webseite keine Ranking-Probleme wegen Duplicate Content hat, muss jede indexierte Seite genügend „Unique Content“ haben. „Unique Content“ sind Inhalte, die nur für eine Seite erstellt wurden und nur auf dieser vorkommen.
Warum ist Duplicate Content ein Problem?
Der Googlebot mag keinen Duplicate Content. Und wenn er zu viel auf einer Domain findet, dann wird er sauer. Die Folge sind Abstrafungen und Zurücksetzungen im Ranking.
Für Google ist Duplicate Content ein großes Thema. Zum einen ist es schwer, algorithmisch herauszufinden, welche Seite einer Domain am passendsten für eine Suchanfrage ist. Außerdem will Google Crawling-Ressourcen sparen und nicht 100 Versionen einer gleichen Seite crawlen, weil das in den Maßstäben von Google wirklich immens viel Geld ist, das an Hardwareleistung verschwendet wird. Die Grundlagen zum Thema gibt es direkt von Google: „Duplizierter Content“.
Ab wann ist Duplicate Content ein Problem?
Ein richtiges Problem mit Duplicate Content hast Du vor allem dann, wenn Google sich nicht entscheiden kann, welche Seite relevanter ist, und sich daher mehrere Seiten im Ranking abwechseln. Aber nachdem Du vermutlich eine Zahl hören möchtest: Sobald Du mehr doppelte als einzigartige Inhalte hast, hast Du ein Problem. Spätestens. Die perfekt suchmaschinenoptimierte Seite besteht aus 100% Unique Content – in der Theorie.
Was sind typische Beispiele für Duplicate Content?
Duplicate Content hat viele Gesichter. Ein paar der Klassiker sind diese:
- Websites, die via https://example.com, http://example.com, http://www.example.com und https://www.example.com erreichbar sind (und nicht weiterleiten)
- Über Groß- und Kleinschreibung erreichbare URLs wie example.com/Beispiel und example.com/beispiel
- Eigene URLs für Druckversionen
- Zusätzliche PDFs mit Produktinfos wie technischen Details, die auch auf der Produkt-Landingpage angegeben werden (sollten)
- Vielzählige Produktdetailseiten zu bestimmten Größen, Farben und Formen
- Parameter für Affiliate-URLs wie ?partnerid=2858
- Parameter-URLs für Sortierung und Darstellung von Produktübersichten
- /index.htm, /de/ und ähnliche Dinge, die Content-Management-Systeme produzieren
- Automatisch generierte Tag-Seiten
- Und in gewisser Form auch Paginierungsseiten
Die Liste lässt sich vermutlich ewig weiterführen. Und irgendwas davon gibt es auf jeder Domain – garantiert.
Wie kannst Du Duplicate Content finden?
Der einfachste Weg, wie Du DC auf Deiner Seite finden kannst, ist Textbausteine zu googlen. Setze den Textbaustein einfach in Anführungszeichen und los geht es:

Um die doppelten Inhalte auch wirklich zu finden, musst Du dann noch auf diesen Link klicken, um auch die herausgefilterten doppelten Seiten anzuzeigen:

Nachdem es aber etwas umständlich wäre, sämtliche Textbausteine zu suchen, gibt es auch hilfreiche Tools. In Googles neuer Search Console gibt es den Report „Indexabdeckung“. Dazu musst Du im Diagramm auf die „Ausgeschlossenen“ klicken:
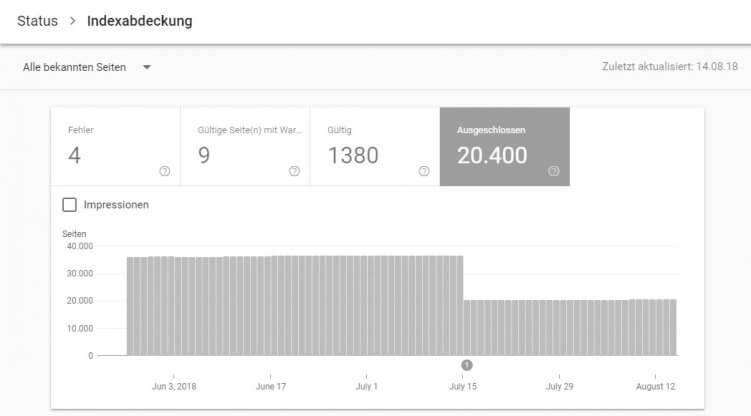
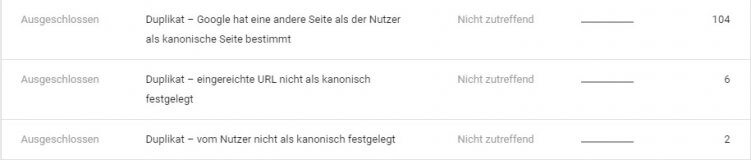
Dann siehst Du unten auch einige Typen, bei denen Google selbst Dir sagt, dass sie eine Seite als Duplikat einer anderen URL eingestuft haben:
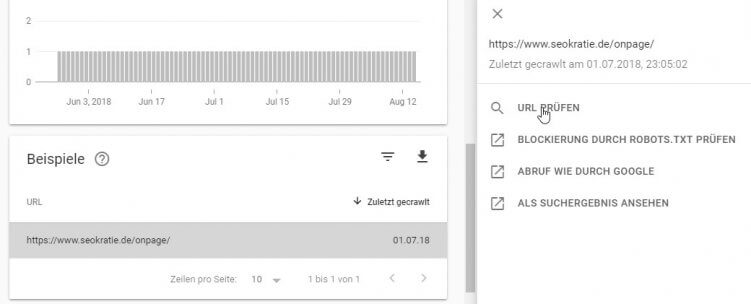
Mit einem Klick auf die betroffene URL klappt sich ein Menü auf, bei dem Du direkt in das URL-Prüfungs-Tool springen kannst. Dort siehst Du dann sogar, welche die doppelte URL ist.
Aber auch über andere Onpage-Tools wie beispielsweise Ryte kannst Du doppelte Inhalte finden. Sinnvollerweise zu finden unter „Inhalt“ > „Duplicate Content“:
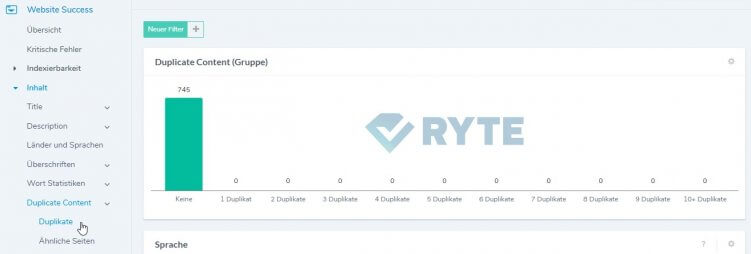
Selbstverständlich sehen bei uns nicht alle Seiten so sauber und grün aus.
Ryte unterscheidet in Duplikate – also komplett doppelte Seiten – und ähnliche Seiten beziehungsweise „Near Duplicate Content“. Letztere sind oft aber sogar gefährlicher, weil sie meist ungewollt sind und von Google nicht einfach als Duplikate aussortiert werden. Beides sind also sehr praktische Reports, um Duplicate Content zu finden.
Wie kannst Du Duplicate Content vermeiden?
Es gibt verschiedene Lösungen, um Duplicate Content zu vermeiden. Die Grundlegendste: DC gar nicht erst entstehen lassen. Es fängt bei einer sauberen Crawlingsteuerung an. Heißt, dass Du doppelte Inhalte nicht verlinken solltest, damit Suchmaschinen sich nicht damit rumschlagen müssen.
Wenn die doppelte Seite aber schon da ist, dann solltest Du sie im Idealfall direkt per 301-Weiterleitung auf die gewollte Original-URL weiterleiten. Dann bleibt Deine Seite schön schlank und gesund.
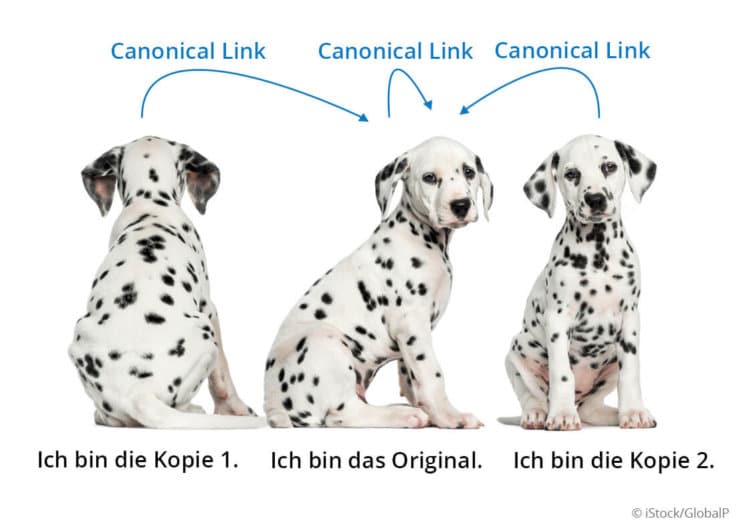
Nun gibt es aber auch doppelte Inhalte, die für Deine Besucher einen Nutzen haben. Beispielsweise URLs mit Sortierungen, Affiliate-URLs oder Produktvarianten. Diese Seiten darfst Du behalten, aber sie müssen per Canonical-Link auf die Original-URL verweisen. So sieht das dann aus:
<link rel=“canonical“ href=“https://www.seokratie.de/duplicate-content-bei-google-vermeiden/“ />
Dieser für Nutzer nicht sichtbare Link im <head> Deiner Seite sagt Suchmaschinen, welche Seite in den Suchergebnissen erscheinen soll. Suchmaschinen verstehen dann die doppelte URL und die Original-URL als einen Inhalt und können damit umgehen.
Wenn Du wissen möchtest, wie Canonicals genau funktionieren, dann lies Luisas ausführlichen Artikel über Canonicals.
Wenn Du doppelte Inhalte hast, die in keiner Version im Index erscheinen sollen – etwa sehr ähnliche Verteilerseiten, die nur zur Navigation dienen – dann solltest Du diese per Robots-Metatag auf „noindex,follow“ stellen, um sie aus Suchmaschinen auszuschließen. Noch besser ist es allerdings, wenn Du die gesamte Existenz dieser Seiten hinterfragst.
Wenn Du doppelte Inhalte hast, die beide über die Suche auffindbar sein sollten, dann hilft nur eins: Du musst diese Inhalte individualisieren. Auch wenn all Deine Services identisch sind, egal ob Du beispielsweise einen Laptop oder Desktop-PC reparierst: Wenn Du willst, dass die Leistungen separat auffindbar sind, musst Du für sie jeweils eigene Inhalten formulieren. Das gilt selbstverständlich auch für Produktbeschreibungen in Online Shops.
Tipp: Duplicate Content durch Druckversionen vermeiden
Statt eigene URLs für Druckversionen zu verwenden, kannst Du übrigens in Deinem CSS für Deine „normalen“ URLs über den Medientyp „print“ eine angepasste Darstellung für den Druck hinterlegen. Das sieht dann in etwa so aus:
@media print {
body {
color: #000;
background-color: #fff;
}
}
Spezialfälle von Duplicate Content
Wiederkehrende Textbausteine
Auch nur einzelne Absätze, die auf mehreren Deiner Seiten vorkommen, sind eine Form von Duplicate Content. Google selbst nennt das „wiederkehrende Textbausteine“:
„Minimieren Sie wiederkehrende Textbausteine: Anstatt am Ende jeder Seite umfangreiche Urheberrechtshinweise einzufügen, können Sie lediglich eine kurze Zusammenfassung mit einem Link zu detaillierten Informationen aufführen.“
Das ist eine nicht unerhebliche Information. Versuche so wenig Text wie möglich in Footer & Co. zu packen. Auch Versandinformationen und andere Dinge sind Duplicate Content! Google reagiert da recht empfindlich, besonders wenn Du 300 Wörter an umfangreichen Infos über Deinen tollen Shop ans Ende jeder einzelnen Webseite packst. Was daran (für den User) schlecht sein soll, weiß ich nicht. Google wird es schon wissen.
Externer Duplicate Content
Wenn Inhalte auf mehreren Domains vorkommen, muss sich Google für ein Original entscheiden. Im Regelfall ist das die Seite, auf der der Googlebot zuerst den Inhalt gefunden hat. Aber auch andere Signale wie beispielsweise Links zur Quelle sind für Google ein Indiz.
Wenn Du also eine Pressemitteilung veröffentlichst und für diese Deine Seite gefunden werden soll, solltest Du sicher gehen, dass Du zuerst veröffentlichst. Entscheidend ist, dass Google Deine Seite zuerst crawlt. Das kannst Du beschleunigen, indem Du in der Google Search Console via „Crawling“ > „Abruf wie durch Google“ bei der abgerufenen URL auf „Indexierung beantragen“ klickst.
Für das Original ist externer Duplicate Content nicht besonders problematisch. Verwendest Du aber Inhalte von Lieferanten für Produktbeschreibungen, werden diese wahrscheinlich auch von anderen Websites verwendet. Dann ist es sehr unwahrscheinlich, dass Deine Seite gefunden wird. Du solltest Deine Produktbeschreibungen daher immer selbst erstellen.
Wenn Du aber Zitate verwendest, ist das in der Regel kein Problem. Um ganz sicher zu gehen, kannst Du diese im Quellcode über das Tag „blockquote“ als Zitate auszeichnen:
Suchst Du eine kompetente, flexbile und zuverlässige Online-Marketing-Agentur? Wir freuen uns auf Deine unverbindliche Anfrage.
Kontaktiere uns<blockquote>Dies ist ein Zitat.</blockquote>
Internationaler Duplicate Content
Wenn Du in Deutschland, Österreich und der Schweiz aktiv bist, hast Du wahrscheinlich jeweils eigene Seiten mit entsprechend angepassten Preisen, Telefonnummern und Versandinformationen. Damit Du in diesem Fall keine Probleme mit Duplicate Content bekommst, wurde die „hreflang“-Auszeichnung erfunden. Damit sagst Du im <head> Deiner Seite den Suchmaschinen, welche der Seiten für welches Land und für welche Sprache gedacht ist. Dieser Code sagt beispielsweise, dass Example.de auf Deutsch und für Deutschland ist, Example.at ist auf Deutsch und für Österreich:
<link rel="alternate" hreflang="de-de" href="https://www.example.de/duplicate-content"/> <link rel="alternate" hreflang="de-at" href="https://www.example.ate/duplicate-content"/>
Für die entsprechenden Details liest Du am besten Luisas ausführlichen Artikel zum Thema hreflang.
Wenn trotz hreflang Chaos ist
Auch mit definierten hreflangs kann es Dir passieren, dass Google zu ähnliche internationale Seiten zusammenfasst – das siehst Du beispielsweise daran, dass in Googles Cache für amazon.at die Seite amazon.de hinterlegt ist:

Auch wenn der Cache nichts mit der Indexierung zu tun hat, ist das ein Indiz dafür, dass die Seiten von Google im Index „zusammengeklappt“ werden. Vermutlich hat das mit Effizienz zu tun. Vor einem Jahr noch führte das zu unschönen Vermischungen zwischen den Ländern und auch zu Rankingproblemen, mit denen viele zu kämpfen hatten. Seit Oktober 2017 spielt Google aber einfach die entsprechende URL für das passende Land aus. Aus unserer Sicht ist es daher (im Regelfall) nicht notwendig, die Inhalte für die verschiedenen Länder zu individualisieren. Für Deine Besucher kann das aber sehr sinnvoll sein.
Wie schlimm ist Duplicate Content wirklich?
Das Schlimme an Duplicate Content ist, dass sich die Auswirkungen meistens gar nicht zeigen. Trotzdem handelt es sich um Ballast auf der Seite, der einen bremst.
Erst wenn Deine Seite Tausende URLs hat und Dein Seitenaufbau dadurch immer komplizierter wird (Canonicals, Hreflang, verschiedene Domains), werden die Probleme so richtig gravierend. Als Hobby-Seitenbetreiber hast Du in der Regel keine großen Probleme mit DC – sofern Du Deine Inhalte selbst schreibst und Du die wildesten Auswüchse Deines Content-Management-Systems im Blick hast.
Wenn Du das Thema SEO noch besser verstehen möchtest, empfehle ich Dir Julians Buch Suchmaschinenoptimierung für Dummies und unseren Newsletter. Und wenn Du mal professionelle Hilfe brauchst, kannst Du Dich natürlich gerne bei uns melden.






Hallo,
ich finde Text sehr gelungen. Wenn ich nicht wüsste, was Duplicate Content ist, dann hätte ich es nach diesem Artikel auf jeden Fall verstanden.
Allerdings habe ich eine etwas ausführlichere Frage zu diesem Thema und hoffe, dass ich endlich eine Antwort finde:
Ich habe vor kurzem die Seite https://beste-proteinriegel.de/ gestartet. Dort habe ich Ratgeber, einzelne Testberichte und jeweils Bestenlisten (auf den Überseiten, z.B. in der Test-Zusammenfassung). In diesen Bestenlisten findet man jeweils 50-70 Wörter Fazit des jeweiligen Riegels wieder. Ist das bereits zu starker Duplicate Content, sodass er sich negativ auf das Ranking der Überseiten (bspw. der Startseite) auswirkt?
Viele Grüße
Marcel
Hi Marcel, es haben ja sowohl die Übersichtsseite als auch die Detailseiten im Verhältnis mehr Content, der nur auf dieser Seite vorkommt. Daher sehe ich das nicht problematisch. Wenn die Startseite allerdings deine wichtigste Seite ist, würde ich alle Teaser trotzdem individuell anfertigen, um noch weniger den Eindruck einer automatisiert erstellten Seite zu machen.
Hi Felix,
vielen Dank für die Antwort!
So habe ich es mir auch gedacht. Ich werde jedoch erst einmal warten, wie sich die Rankings über die nächsten Monate beobachten. Wenn sie sich nicht wie gewünscht entwickeln, schaue ich einmal, ob ich die Teaser anpassen kann. Insbesondere wenn es an die 100 getesteten Riegel werden nimmt der Duplicate Content sonst sicher überhand.
Toller Beitrag, vor allem, weil Webseiten-Betreiber, die sich in Sachen SEO und Content Marketing noch nicht so gut auskennen, hier viel Wissenswertes mitbekommen.
Ein Problem in vielen Unternehmen, die im Online-Marketing noch hinterherhinken, ist, dass diese nicht verstehen, wie Interne Prozesse, z. B. die Datenpflege im PIM, Auswirkungen auf einen Online-Shop haben. Einfach mal eine bestehende Kategorie umbenennen oder denselben Namen nochmals unter einer anderen Kategorie verwenden, wo auch noch derselbe Texte gepflegt wird, fatal. Auch problematisch, das Produkte in mehreren Kategorien angesiedelt werden.
Mit deinen Tipps und Tricks kann aber jeder Webseiten- und Shop-Betreiber in Sachen Duplicate-Content eine Menge lernen. Danke für den wertvollen Beitrag 🙂
Hi Dennis, danke dir! Du hast sehr recht. Im Idealfall hat das jeder auf dem Schirm, der mit dem Shopsystem arbeitet, ja. Aber in der Regel hilft da nur gutes Monitoring. 😉
Hallo Felix, ein echt guter Text, der einem das Thema verständlich rüber bringt. Zu dem Thema hreflang und unterschiedliche Länderseite habe ich noch eine Frage: Wertet es Google als DC und negativ, wenn mehrere Subdomains wie bspw. ru.example.com, fr.example.com, pl.example.com die gleichen (englischen) Inhalte haben? Die Inhalte in der jeweiligen Landessprache sollen sukzessive nachgezogen werden, aber solange hätten alle Subdomains den gleichen Content in einer Sprache. Wirkt sich das negativ aus? Sind hier hreflang Auszeichnungen notwendig? Besten Gruß, Thomas
Hi Thomas, vielen Dank. Ja, gerade dann brauchst du hreflang. Für die Erklärung dazu im Detail haben wir einen eigenen Blogpost geschrieben: https://www.seokratie.de/hreflang/ Hoffe das hilft dir weiter! 🙂
Hallo Felix,
vielen Dank für diesen informativen und sehr anschaulichen Beitrag!
Dankbar wäre ich Dir, wenn Du noch etwas dazu schreiben könntest, wie es sich mit der Gefahr von negativen Auswirkungen von Duplicate Content verhält, wenn ich zunächst auf meinem Blog einen Beitrag veröffentliche und davon von verschiedenen Profilen mit einem Textauszug des Blogbeitrags auf diesen verlinke.
Viele Grüße
Detlef
Hallo Detlef, danke für deinen Kommentar und entschuldige die späte Rückmeldung. Wenn auf den linkgebenden Seiten der kopierte Inhalt der einzige Inhalt ist, wird diese Seite sehr wahrscheinlich ignoriert. Gefahr für die verlinkte Seite sehe ich dabei aber nicht. Mit Textausschnitten zu arbeiten ist ja relativ üblich. Sicherlich würde es der linkgebenden Seite und somit auch dem Link mehr Relevanz zuweisen, wenn der verweisende Inhalt komplett unique ist. Aber negative Auswirkungen befürchte ich da nicht.
Ich finde den Text auch sehr interessant. Als Übersetzer frage ich mich natürlich inwieweit man dann noch für Übersetzungen von Webcontent computergestützte Übersetzung verwenden kann. Das ist ein Mix aus linguistischen Regeln und Statistik, das heißt die Software übernimmt bereits vorübersetzte Satzfragmente und teils komplette Sätze aus anderen Texten. Oder ist es dann nicht besser für den Kunden rein menschliche Texte anzubieten, um unique content zu erzeugen, also translation/transcreation bzw. copy writing.
Solange es irgendwie möglich ist, würde ich auch immer auf rein menschliche Texte setzen. Nachdem solche Texte ja auch verkaufen sollen, ist es enorm wichtig, dass die flüssig wirken.
Wie vermeide ich denn DC in einem Online Shop, der viele ähnliche Artikel verkauft? Wir haben z.B. eine große Auswahl für Banner mit fertigen Motiven.
Die Artikeltitel unterscheiden sich, jedoch sind die Beschreibungen immer gleich, da wir dort keine große Möglichkeit haben, individuell zu werden und zu jedem Artikel etwas anderes schreiben können.
Gibt es hier eine Möglichkeit oder einen Tipp/Trick, um DC zu vermeiden?
Hi Sascha, Tricks gibt es sicherlich auch, aber am saubersten ist es, zum Beispiel mit Kundenbewertungen zu arbeiten. Oder mehr Produktbilder und Produktdaten zu liefern – ähnliche Produkte, irgendetwas, was die Produktseiten von der Konkurrenz abhebt. Wenn ihr die einzigen mit diesem speziellen Motiv seid, dann werdet ihr vermutlich auch so ranken. Wenn es andere gibt, dann müsst ihr mehr liefern als diese. Keine leichte Aufgabe tatsächlich! Im Zweifel aber kurze, passende und sympathische (verkaufsfördernde) Textschnipsel texten lassen.
Hallo Felix, danke schonmal für’s Feedback. Es ist so, wir haben Artikel, die bieten auch nur wir an, allerdings haben wir diese Artikel z.B. in blau, grün und gelb. Die Grunddaten der Artikel ändern sich eben nicht und lediglich die Farbe ist anders. Dementsprechend haben wir da halt auch Duplicate content. Varianten wären übrigens keine Option, da die Farben jetzt nur vereinfacht darstellen sollen, was ich meine. ????
Nun für jede Farbe einen eigenen Text schreiben, wäre natürlich eine Möglichkeit, aber nicht ganz zielführend, da es ja den Kunden nicht unbedingt interessiert, warum der Artikel Geld oder grün ist.
Wenn ich es jetzt aber richtig verstanden habe, würden aber z.b. Crossselling Artikel unter dem Artikel schon etwas helfen, den duplicate content zu vermindern?
Ich klicke mich aber nochmal etwas durch eure Seite, hatte da vorhin auch ein Video entdeckt in Bezug und DC und Onlineshops.
Mit freundlichen Grüßen
Sascha
Hi Sascha, in dem Fall denke ich, hilft dir Crossselling nicht viel weiter, denn das macht noch keinen wirklichen Unique Content aus. Scheinbar meinst du ja, dass es für all diese Einzelprodukte eine eigene Suchintention gibt – sonst wären ja Canonicals oder Noindex eine Option. Wenn es eine gezielte Suchintention gibt, sollte es meiner Meinung nach auch möglich sein, gezielt zu beschreiben, was das besondere an dem Produkt ist – ohne nur die Farbe zu erwähnen. Das wird zwar keinen Literaturnobelpreis gewinnen, aber in der Theorie müsste das, finde ich, möglich sein. Sonst solltest du deren Indexierung hinterfragen.
Hallo, ich möchte eine Dienstleistung zum Thema sprachen lernen anbieten, und zwar zu vielen unterschiedlichen Sprachen. Die Dienstleistung an sich ist aber immer die gleiche (eine spezielle Art zu lernen).
D. h. ich könnte z. b. eine Seite zum Thema „englisch lernen“ erstellen. EXAKT DIE GLEICHE SEITE könnte ich zum Thema französich, spanisch, italienisch, etc lernen erstellen, ich würde nur statt „englisch“ die jeweils andere sprache schreiben. Aber das wäre ja eindeutig Duplicate Content, oder nicht?? Was wäre die Alternative?
Ich könnte mit dem canonical-tag eine original seite bestimmen, z. b. „englisch lernen“, mit dem tag von ALLEN anderen Seiten auf die „englisch lernen“-Seite verlinken, oder? aber dann würden all die anderen Seiten gar nicht in den SERP´s auftauchen, oder? Das wäre ja ein massiver Nachteil. D. h. wenn jemand nach „spanisch lernen“ googelt dann würde in den SERP´s meine Original-Seite „englisch lernen“ auftauchen. Das ist doch schlecht…oder es taucht gar keine meiner Seiten in den SERP´s auf? Das wäre noch schlechter.
Ich habe gelesen, dass es gut wäre, wenn man auf jeder Seite eigenen, also jeweils neu formulierten Content schreibt. Ich wüsste aber nicht, wie ich die Dienstleistung auf 10 verschiedene Arten beschreiben soll, bzw. wenn ich es tue, dann benutze ich bestimmte Worte (sprachschule, sprachkurs, sprache schnell lernen, und noch viele mehr) immer wieder, entweder weil sie gut passen, oder weil es Begriffe sind nach denen die Leute suchen, d. h. zumindest diese wichtigen Begriffe wären auf allen 10 Seiten gleich…wäre das dann nicht auch Duplicate Content? Falls ja, dann müsste ich diese Begriffe weniger benutzen, aber das ist ja total kontraproduktiv, weil wie gesagt diese begriffe gut meine Dienstleistung erklären UND nach Ihnen gesucht wird….also auch nicht wirklich ein gute Lösung, oder? Oder ist es vielleicht doch möglich die Seiten auf 10 verschiede Arten zu beschreiben UND dabei diese wichtigen Begriffe durchaus oft zu benutzen, aber irgendwie so, dass es doch kein Duplicate Content ist???
Was mir noch einfällt wäre, NUR EINE Seite zu erstellen, und auf dieser zu erklären, dass ich diese Dienstleistung für verschiedene Sprachen anbiete, aber da sehe ich den Nachteil, dass ich die einzelnen Worte „englisch“, oder “französisch“ oder „spanisch“ , und die restlichen Sprachen nicht oft verwenden kann. Sagen wir jemand googlet nach „englisch lernen“, und aus SEO-Sicht wäre es gut auf der Seite die ranken soll 10x „englisch“ einzubinden, das ginge, aber dann wäre da kein Platz mehr für 10x „französisch“, „spanisch“, etc. D. h. diese EINE Seite würde für englisch lernen evtl. gut ranken, aber kaum für die anderen Sprachen, oder??? Ausserdem ist es wohl auch aus verkaufstaktischer Sicht vermutlich besser dem Kunden der englisch lernen will eine Seite anzuziegen die EXAKT zum Thema „englisch lernen“ erstellt worden ist, und nicht eine auf der er theoretisch auch noch andere sprachen lernen könnte. Also auch ne schlechte Lösung…was ist in so einem Fall die best practise? danke
Hallo Felix,
erst einmal vielen Dank und ein großes Lob, dass Du bzw. Ihr Euch die Zeit nehmt, die Kommentare zu beantworten.
Es geht bei uns halt um Bauzaunbanner mit Motiven.
Das heißt, es gibt z.B.
Produkt A – Bauzaunbanner mit Motiv Erdbeeren
Porudkt B – Bauzaunbanner mit Motiv Kirschen
Die Eigenschaften des Banners sind eben gleich und einen komplett individuellen Text nur zum Motiv zu schreiben, wird etwas schwierig bzw. ist dem Kunden vermutlich auch „egal“ 😉
Habe nun gelesen, man könnte z.B. einfach alle Artikel via Canonical Link auf einen „Haupt-Artikel“ verweisen, um DC zu vermeiden. Würde das Sinn machen?
Gruß Sascha
Hallo Felix,
ein super Text der die Thematik gut verständlich durchleuchtet.
Meine Frage geht jedoch etwas tiefer in den Bereich Shopsysteme, wir relaunchen diesen Herbst unser Reiseportal unter neuem Namen und möchten besonders bei den zahlreichen Reisebeschreibungen verschiedener Veranstalter DC vermeiden. Da Gäste über unsere Landingpages zu den einzelnen Angeboten geführt werden ist es nicht nötig spezifische Angebote zu ranken. Wäre die Verwendung der noindex Funktion hier Praktikabel damit wir die originalen Reisebeschreibungen verwenden können ohne DC zu produzieren und negative Auswirkungen auf unser Ranking zu provozieren?
Viele Grüße
Daniel
Hallo Felix,
vielen Dank für deinen Beitrag und dein hilfreiches Feedback hier in den Kommentaren. Vielleicht kannst du mir bei folgenden Punkten weiterhelfen.
Wir haben einige lokale Geschäftsstellen (>50) mit eigenen Webseiten. Auf diesen gibt es zum Teil identische Texte, zum Beispiel die Seiten, die Inhalte über uns (Beschreibungen wer wir sind und was wir tun) beinhalten. Zusätzliche haben unsere lokalen Geschäftsstellen aber auch die Möglichkeit, individuelle Inhalte hinzuzufügen.
Ich habe es so verstanden, dass je mehr individueller Content auf einer Seite vorhanden ist, desto weniger problematisch ist der allgemeine (doppelte) Content. Ist das korrekt? Gibt es da so etwas wie eine Quote? Oder wurde so etwas mal getestet?
Außerdem die Frage, ob Google die allgemeinen Inhalte womöglich gar nicht als Duplicate Content wertet, da es erkennt, dass die verschiedenen Seiten zu ein und demselben Unternehmen gehören (die Seiten laufen auf derselben Domain, unterscheiden sich allerdings in der Subdomain, haben dieselben Infos im Impressum, haben dasselbe Layout etc.).
Wie schätzt du das ein?
Hallo Daniel, in dem Fall klingt das tatsächlich nach einer praktikablen Lösung. So habt ihr die Inhalte für den Nutzer, versteckt nichts, habt aber auch keine Duplikate im Index. Trotzdem solltet ihr euch die Frage stellen: Wenn die Inhalte identisch mit denen der verlinkten Seiten sind, haben die Seiten dann wirklich einen Sinn? Möglicherweise ja, aber die generelle Struktur zu hinterfragen schadet nicht.
Hallo Simon, das klingt nach einem recht komplexen Fall, der sich in den Kommentaren nur schwer beantworten lässt. Jede Geschäftsstelle hat ja vermutlich einen lokalen Bezug und somit eine eigene Suchanfrage/Suchintention. Dann haben zumindest alle Seiten eine Berechtigung, aber trotzdem Duplicate Content. Am besten überlegt ihr euch eine Art Anreizsystem, damit die Geschäftsstellen die individuellen Inhalte pflegen. Zusätzlich könnt ihr schauen, wie ihr die anderen Seiten (Impressum & Co.) zusammenlegen könnt. Ich würde auf jeden Fall dran arbeiten, gut klingt das nicht.
Hi Sascha, ja, in der Tat kannst du dann einen Canonical auf einen Hauptartikel (Bestseller) setzen. Und sollten einige Leute gezielt nach einem Erdbeer-Bauzaun suchen, dann kannst du diese mit Inhalten anreichern und den Canonical entfernen.
Hallo Molzer, danke für deinen Kommentar. Wenn es eigene Dienstleistungen sind, dann sollten sie auch eigene Inhalte haben. In diesem Fall kann ein WDF-IDF-Tool helfen: Dieses sagt dir, über welche Unterthemen üblicherweise bei der jeweiligen Sprache geschrieben wird. Außerdem interessant: Wer ist der Dozent? Was zeichnet diesen aus? Es gibt sicher Besonderheiten und USPs, die sich herausstellen lassen.
Hallo Felix,
danke für diesen wissensreichen Beitrag. Ich bin gerade dabei mich für unsere Firma in das Thema SEO tiefer einzuarbeiten.
Da bin ich auf den Umstand gestoßen, dass die (in Dtl.) Pflichtseiten Impressum und Datenschutz ja eigentlich Duplicate Content sein müssten, da diese ja überall gleich aufgebaut sind und in vielen Fällen von Generatoren wie z.B. von eRecht24 sind.
Da wäre jetzt meine Frage an Dich, ob Du empfiehlst das Impressum sowie die Datenschutzerklärung aus dem Index zu nehmen bzw. die Links im Footer auf „nofollow“ zu setzen, um den Linkjuice nicht auf diese (für das Ranking) unnötige Seite zu leiten und damit zu „verschwenden“.
Wäre cool, wenn Du hier Deine Best Practices nennen könntest.
Danke für Deine Hilfe und vielen Dank im Voraus.
Gruß Timo
Hi Timo,
spannende Frage, danke. 🙂 Da es sich hier nur um einzelne Seiten handelt, die ja nicht direkt ranken sollen, ist das nicht so schlimm. Die Datenschutzerklärung würde ich in der Regel deindexieren. Beim Impressum bevorzugen es viele, das im Index zu behalten.
Die Links dorthin mit nofollow zu versehen, bringt Dir allerdings keinen Vorteil. Dadurch gewinnen die anderen Links nicht an Stärke. Nofollow würde ich daher nicht verwenden.
Ich hoffe das hilft Dir!
Hallo, darf ich eine Frage stellen:
Inpressum und Datenschutzerklärungen werden haufenweise kostenlos von Datenschutz-Generatoren angeboten.
Somit haben haufenweise Websites so einen gleichformulierten Text. (was ja offensichtlich auch Sinn macht, denn es muss ja gesetzeswasserdicht sein)
Ist somit das Impressum und die DS-Erklärung doppelter Content, weil tausende Seite den selben Text haben?
Liebe Grüße
Hallo,
ich nochmal….
habe jetzt erst gesehen, dass ganz unten Timo so eine Frage gestellt hat… sorry, habe nicht tief genug gescrollt.
In Deiner Antwort sprichst Du von „deindexieren“.
Als kleine Massagepraxis habe ich (nur) eine sog. „Baukasten-Homepage“, somit habe ich keinen großen Einfluss auf HTML-Befehle für den Quelltext.
Könnte ich diese „gesetzlich wasserdicht“ vorgegebenen Formulierungen (insbesondere des megalangen DS-Textes) auch als png oder jpg einfügen?
….oder gar auslagern und verlinken auf (m)eine andere Website?
Damit meine Firmen Website frei ist von doppeltem Content…?
nochmal Liebe Grüße
Hallo Anja, ich würde mir da keinen allzu großen Kopf machen. Wie du schon sagst: Das geht vielen Websites so und Google weiß das. Lass die Seite dann lieber so wie sie ist, bevor du alles als Bild einfügst. Deindexieren wäre zwar besser, wenn es möglich ist. Aber auch so wird das deinem Ranking nicht spürbar schaden.
Hallo Felix,
vielen Dank für deine wertvollen Double-Content-Infos!
Ich hoffe ich habe nichts überlesen. Aber eins ist mir noch nicht ganz klar: wenn ich auf einer etablierten Webseite mit selbstgeschriebenem Blog auch eine Unterseite mit Inhalten eines externen Informationsdienstes (also keinem unique content) etabliere, muss ich mir Sorgen machen, dass die Webseite als Ganzes (und somit die Sichtbarkeit meiner Blogbeiträge) von Google abgestraft wird? Oder lediglich die Unterseiten des Infodienstes nicht gut gefunden werden?
Ich bedanke mich herzlich! LG, Cathrin
Hallo, ich habe auch Fragen 😉
Es gibt doch immer Inhalte, welche auf verschiedenen Seiten vorkommen.
Z.B. bei Stellenangeboten. Wenn jede Stelle eine eigene Unterseite hat, dann kommt es durch die Vorstellung der Firma / des Standortes immer zu Duplicate Content. Ja, man könnte solche Texte immer abändern, aber es muss doch elegantere Lösungen geben.
Hoffentlich wurde diese Frage noch nicht gestellt, aber ich stelle mir einen Codeschnipsel vor. „Hallo Crawler, von hier bis hier nicht beachten“.
Weitere Beispiele:
Im Onlineshop hatte ich den Fall, dass wir bei jedem Artikel einen Lieferhinweis in der Artikelbeschreibung einblenden mussten.
Auf meiner Seite https://kemod.de sind es Google Bewertungen, welche ich durch ein Plugin auf verschiedenen Seiten anzeigen lasse.
Iframe sind auch Duplicate Content – richtig?
Ich bin für jede Hilfe dankbar! Super Beitrag und echt viel Input. Sorry, falls meine Frage schon beantwortet wurde 😉
Lieben Gruß
Hallo Keno, danke für deinen Kommentar! Tatsächlich wäre es sehr schön für SEOs, wenn es so etwas gäbe. Das wäre mir aber nicht bekannt. Wahrscheinlich weil das Tür und Tor öffnen würde, überall mit ausufernden doppelten Inhalten um sich zu schmeißen.
Ich bin überzeugt, dass Google schon damit umgehen kann, dass sich einige Elemente wiederholen. Dann wird dieser Textblock vermutlich relativ automatisch als irrelevant eingestuft, weil eben Duplicate Content. Solange der Anteil an uniquem, wertvollem Content überwiegt, sollte das nicht allzu schädlich sein. In Maßen. Vermeiden würde ich so etwas wie einen wiederkehrenden (längeren) Lieferhinweis definitiv auch!